PDF Exam Questions and Answers : C1000DEV Exam Braindumps contains complete pool of C1000DEV Questions and answers in PDF format. PDF contains actual Questions with April 2024 updated MongoDB Certified Developer Associate Braindumps that will help you get high marks in the actual test. You can open PDF file on any operating system like Windows, MacOS, Linux etc or any device like computer, android phone, ipad, iphone or any other hand held device etc. You can print and make your own book to read anywhere you travel or stay. PDF is suitable for high quality printing and reading offline.
VCE Exam Simulator 3.0.9 : Free C1000DEV Exam Simulator is full screen windows app that is like the exam screen you experience in actual test center. This sofware provide you test environment where you can answer the questions, take test, review your false answers, monitor your performance in the test. VCE exam simulator uses Actual Exam Questions and Answers to take your test and mark your performance accordingly. When you start getting 100% marks in the exam simulator, it means, you are ready to take real test in test center. Our VCE Exam Simulator is updated regularly. Latest update is for April 2024.
MongoDB C1000DEV Exam Braindumps
We offer MongoDB C1000DEV Exam Braindumps containing actual C1000DEV exam questions and answers. These Exam Braindumps are very useful in passing the C1000DEV exams with high marks. It is money back guarantee by killexams.com
Real MongoDB C1000DEV Exam Questions and Answers
These C1000DEV questions and answers are in PDF files, are taken from the actual C1000DEV question pool that candidate face in actual test. These real MongoDB C1000DEV exam QAs are exact copy of the C1000DEV questions and answers you face in the exam.
MongoDB C1000DEV Practice Tests
C1000DEV Practice Test uses the same questions and answers that are provided in the actual C1000DEV exam pool so that candidate can be prepared for real test environment. These C1000DEV practice tests are very helpful in practicing the C1000DEV exam.
MongoDB C1000DEV Exam Braindumps update
C1000DEV Exam Braindumps are updated on regular basis to reflect the latest changes in the C1000DEV exam. Whenever any change is made in actual C1000DEV test, we provide the changes in our C1000DEV Exam Braindumps.
Complete MongoDB C1000DEV Exam Collection
Here you can find complete MongoDB exam collection where Exam Braindumps are updated on regular basis to reflect the latest changes in the C1000DEV exam. All the sets of C1000DEV Exam Braindumps are completely verified and up to date.
Killexams.com C1000DEV Exam Braindumps contain complete question pool, updated in April 2024 including VCE exam simulator that will help you get high marks in the exam. All these C1000DEV exam questions are verified by killexams certified professionals and backed by 100% money back guarantee.
- test Name: C1000DEV MongoDB Certified Developer Associate
- test Code: C1000DEV
- test Duration: 90 minutes
- test Format: Multiple-choice questions
- Passing Score: 65% or higher
Course Outline:
1. Introduction to MongoDB and Data Modeling
- Overview of MongoDB and its key features
- Introduction to NoSQL databases and document-oriented data model
- Designing effective MongoDB data models
2. CRUD Operations and Querying MongoDB
- Performing create, read, update, and delete operations in MongoDB
- Querying data using MongoDB Query Language (MQL)
- Working with indexes and optimizing query performance
3. Aggregation Framework and Data Analysis
- Understanding the MongoDB Aggregation Framework
- Performing data analysis and complex aggregations
- Utilizing pipeline stages, operators, and expressions
4. Data Replication and High Availability
- Configuring replica sets for data replication and high availability
- Managing replica set elections and failover
- Implementing read preference and write concern
5. MongoDB Security and Performance Optimization
- Securing MongoDB deployments using authentication and authorization
- Implementing access controls and user management
- Monitoring and optimizing MongoDB performance
Exam Objectives:
1. Demonstrate knowledge of MongoDB fundamentals, including its data model and key features.
2. Perform CRUD operations and write queries using MongoDB Query Language.
3. Understand and utilize the MongoDB Aggregation Framework for data analysis.
4. Configure and manage MongoDB replica sets for data replication and high availability.
5. Implement MongoDB security measures and optimize performance.
Exam Syllabus:
The test syllabus covers the following courses (but is not limited to):
- MongoDB fundamentals and data modeling
- CRUD operations and querying MongoDB
- Aggregation Framework and data analysis
- Data replication and high availability with replica sets
- MongoDB security and performance optimization
We are doing struggle on providing valid and updated C1000DEV dumps braindump questions and answers, along with vce test simulator for C1000DEV braindumps practice. Our experts keep it updated and keep connected to people taking the C1000DEV test. They update C1000DEV dumps as necessary and maintain high quality of material so that test takers really benefit from it.
C1000DEV Dumps
C1000DEV Braindumps
C1000DEV Real Questions
C1000DEV Practice Test
C1000DEV dumps free
MongoDB
C1000DEV
MongoDB Certified Developer Associate
http://killexams.com/pass4sure/exam-detail/C1000DEV Question: 91
Which two statements are true about Salesforce B2B Commerce Price Lists? Choose 2 answers
A. A price list is specific to a certain currency.
B. A price list may be set to become enabled In the future.
C. A price list must contain prices for all products in the system.
D. A price list may only be associated with a single user. Answer: A,B Question: 92
Which two statements are true about Salesforce B2B Commerce Price Lists? Choose 2 answers
A. A price list is specific to a certain currency.
B. A price list may be set to become enabled In the future.
C. A price list must contain prices for all products in the system.
D. A price list may only be associated with a single user. Answer: A,B Question: 93
Which two statements are true about Salesforce B2B Commerce Price Lists? Choose 2 answers
A. A price list is specific to a certain currency.
B. A price list may be set to become enabled In the future.
C. A price list must contain prices for all products in the system.
D. A price list may only be associated with a single user. Answer: A,B Question: 94
Which two statements are true about Salesforce B2B Commerce Price Lists? Choose 2 answers
A. A price list is specific to a certain currency.
B. A price list may be set to become enabled In the future.
C. A price list must contain prices for all products in the system.
D. A price list may only be associated with a single user. Answer: A,B Question: 95
Which two statements are true about Salesforce B2B Commerce Price Lists? Choose 2 answers
A. A price list is specific to a certain currency.
B. A price list may be set to become enabled In the future.
C. A price list must contain prices for all products in the system.
D. A price list may only be associated with a single user. Answer: A,B Question: 96
Which two statements are true about Salesforce B2B Commerce Price Lists? Choose 2 answers
A. A price list is specific to a certain currency.
B. A price list may be set to become enabled In the future.
C. A price list must contain prices for all products in the system.
D. A price list may only be associated with a single user. Answer: A,B Question: 97
Which two statements are true about Salesforce B2B Commerce Price Lists? Choose 2 answers
A. A price list is specific to a certain currency.
B. A price list may be set to become enabled In the future.
C. A price list must contain prices for all products in the system.
D. A price list may only be associated with a single user. Answer: A,B Question: 98
Which two statements are true about Salesforce B2B Commerce Price Lists? Choose 2 answers
A. A price list is specific to a certain currency.
B. A price list may be set to become enabled In the future.
C. A price list must contain prices for all products in the system.
D. A price list may only be associated with a single user. Answer: A,B Question: 99
Which two statements are true about Salesforce B2B Commerce Price Lists? Choose 2 answers
A. A price list is specific to a certain currency.
B. A price list may be set to become enabled In the future.
C. A price list must contain prices for all products in the system.
D. A price list may only be associated with a single user. Answer: A,B Question: 100
Which two statements are true about Salesforce B2B Commerce Price Lists? Choose 2 answers
A. A price list is specific to a certain currency.
B. A price list may be set to become enabled In the future.
C. A price list must contain prices for all products in the system.
D. A price list may only be associated with a single user. Answer: A,B
For More exams visit https://killexams.com/vendors-exam-list
Kill your test at First Attempt....Guaranteed!
MongoDB Certified basics - BingNews
https://killexams.com/pass4sure/exam-detail/C1000DEV
Search resultsMongoDB Certified basics - BingNews
https://killexams.com/pass4sure/exam-detail/C1000DEV
https://killexams.com/exam_list/MongoDBHow SuperDuperDB delivers an easy entry to AI appsSuperDuperDB
Numerous observers have predicted that 2024 will be the year enterprises turn generative AI such as OpenAI's GPT-4 into actual corporate applications. Most likely, such applications will begin with the simplest kinds of infrastructure, stringing together a large language model such as GPT-4 with some basic data management.
Enterprise apps will start with simple tasks such as searching through text or images to find the match to a natural-language search.
A perfect candidate to make that happen is a Python library called SuperDuperDB, created by the venture capital-backed company of the same name, founded this year.
SuperDuperDB is not a database but an interface that sits between a database such as MongoDB or Snowflake and a large language model or other GenAI program.
That interface layer makes it simple to perform several very basic operations on corporate data. Using natural language queries in a chat prompt, one can query an existing corporate data set -- such as documents -- more extensively than is possible with a typical keyword search. One can upload images of, say, products to an image database and then query that database by showing an image and looking for a match.
Likewise, moments in videos can be retrieved from an archive of videos, by typing themes or features. Records of voice messages can be searched as a text transcript, making a basic voicemail assistant.
The technology also has uses for data scientists and machine learning engineers who want to refine AI programs using proprietary corporate data.
For example, to "fine-tune" an AI program such as an image recognition model, one has to hook up an existing database of images to the machine learning program. The challenge is how to get the image data into and out of the machine learning program, and how to define variables of the training process, such as the loss to be minimized. SuperDuperDB offers simple function calls to simplify all those things.
A key aspect of many of those functions is to convert different data types -- text, image, video, audio -- into vectors, strings of numbers that can be compared against one another. Doing so allows SuperDuperDB to perform "similarity search," where the vector of a text phrase, for example, is compared to a database full of voicemail transcripts to retrieve the message most closely matching the query.
Mind you, SuperDuperDB is not a vector database like Pinecone, a commercial program. It's a simpler form of organizing vectors called a "vector index."
The SuperDuperDB program, which is open-source, is installed like a typical Python installation from the command line or loaded as a pre-built Docker container.
The first step to working with SuperDuperDB can either be setting up a data store from scratch, or working with an external data store. In either case, you'll want to have a data repository such as MongoDB or a SQL-based database.
SuperDuperDB handles all data, including newly created data and data fetched from the database, via what it calls an "encoder," which lets the programmer define data types. These encoded types -- text, audio, image, video, etc. -- can be stored in MongoDB as "documents" or in SQL-based databases as a table schema. It's also possible to store very large data items, such as video files, in local storage when they exceed the capacity of either MongoDB or the SQL database.
Once a data set is chosen or created, neural net models can be imported from libraries such as SciKit-Learn or one can use a very basic built-in inventory of neural nets such as the Transformer, the original large language model. One can also call APIs from commercial services such as OpenAI and Anthropic. The core function of having the model make predictions is done with a simple call to a ".predict" function built into SuperDuperDB.
When working with a large language model or an image model like Stable Diffusion or Dall-E, the neural net will seek to retrieve answers from the database by performing the vector similarity search. That's as simple as calling a ".like" function and passing it the query string.
It's possible to make more complex apps by assembling multiple stages of functionality with SuperDuperDB, such as using similarity search to retrieve items from a database and then passing those items to a classifier neural net.
The company has added functions that make an app more of a production system. They include a service called Listeners that re-run predictions whenever the underlying database is updated. Various functions in SuperDuperDB can also be run as separate daemons to Boost performance.
This year will witness a great deal of evolution in programs such as SuperDuperDB, making them more robust still for production purposes. You can expect SuperDuperDB to evolve alongside other important emerging infrastructures such as the LangChain framework and commercial tools such as the Pinecone vector database.
While there's a lot of ambitious talk about enterprise use of GenAI, it probably starts right here, with the kinds of humble tools that can be picked up by the individual programmer.
Tue, 02 Jan 2024 17:16:00 -0600entext/htmlhttps://www.zdnet.com/article/how-superduperdb-delivers-an-easy-entry-to-ai-apps/You Can Get Microsoft Office and These Basic Training Courses for $40 Right Now
We may earn a commission from links on this page.
You can get a lifetime license to Microsoft Office 2019 for Windows—complete with Word, Excel, PowerPoint, Outlook, Publisher, Access, and OneNote—on sale for $39.97 right now (reg. $288) through January 7. If you're new to using Office (or just rusty), this is a bundle that also comes with 106 lessons and seven hours of content to learn how to use Word, PowerPoint, Outlook, and Excel more effectively. After buying, your license keys and download links will be emailed and ready to install.
You can get Microsoft Office Professional Plus 2019 along with the training courses on sale for $39.97 right now (reg. $288) until January 7 at 11:59 p.m. PT, though prices can change at any time.
Wed, 03 Jan 2024 09:00:00 -0600entext/htmlhttps://lifehacker.com/tech/microsoft-office-2019-with-training-coursesEarn top-flight IT certifications with this CompTIA training bundle for under $65No result found, try new keyword!Macworld Certification is key among IT professionals. But while more than 90% of IT experts have at least one certification, fewer than 25% hold a coveted CompTIA A+ certification, an entry-level ...Thu, 04 Jan 2024 18:44:28 -0600en-ustext/htmlhttps://www.msn.com/MongoDB World 2016: Sumo Logic App for MongoDB, Infusion’s collaboration,…
MongoDB held its user conference in New York City this week, where more than 2,000 attendees gathered to network and learn more about how they can utilize the NoSQL database.
“With data and analytics powering companies in every sector, the MongoDB community continues to grow rapidly,” said Dev Ittycheria, president and CEO of MongoDB. “MongoDB World brings together this community of independent developers and IT professionals, from startups to Fortune 100 companies, to collaborate on giant ideas and how they are building the world’s most innovative, modern applications.”
In addition to MongoDB’s Atlas and Connector for Apache Spark announcements, other companies had news about products designed to Boost their support for MongoDB.
Sumo Logic teams up with MongoDB for monitoring and troubleshooting Sumo Logic announced its Sumo Logic App for MongoDB, designed to provide developers a deeper view of the health and performance of their MongoDB Deployments. The new solution provides a way to monitor, optimize and secure modern apps. Users can get a complete overview of their infrastructure in one interface; identify and isolate issues; and speed up deployment.
“Today’s IT teams are struggling with getting a deep, holistic view into the health of their database deployments, so they can [better] monitor performance, diagnose problems and audit access to identify potential risks,” said Bruno Kurtic, founding vice president of product and strategy for Sumo Logic. “The Sumo Logic App for MongoDB provides a modern solution built on machine data analytics that integrates with MongoDB environments to provide actionable intelligence in a unified, content-aware view across all applications and supporting infrastructure.”
Infusion and MongoDB announce strategic partnership MongoDB certified partner Infusion announced its plans to collaborate with MongoDB in order to provide businesses actionable information about their data. Infusion and MongoDB will work to redefine the way users interact and view data and help them build modern apps that leverage IoT and data analytics built on MongoDB.
“MongoDB and Infusion have been able to successfully develop combined, high-quality integration solutions that have been hugely impactful for our clients,” said Alim Somani, president of Infusion. “Together, we are focused on helping our clients get the most value from their data, by delivering solutions focused on application modernization, customer experience, enterprise productivity and business insights that provide them deep insight into their operations and enable them to make smarter decisions that truly drive their businesses forward.”
Happiest Minds aims to help users migrate from RDBMS to MongoDB Happiest Minds, a digital transformation, infrastructure, security and engineering services provider, announced the launch of R2M. R2M is designed to help the performance, scalability and management of new-generation Web apps. The solution features built-in monitoring APIs, and has proven its automated migration to MongoDB is 40% to 50% faster than other solutions.
“The relational database has been the pillar of enterprise data management for more than a few decades,” said Prasenjit Saha, president of infrastructure management and security services at Happiest Minds Technologies. “The growth in data sources and user loads is pushing these databases beyond their limits, and the search for alternatives to meet the ever-changing market and data needs is vital. R2M will allow our clients to seamlessly migrate to these new alternatives and enhance the benefits they enjoy from today’s best solutions.”
Basis Technology announces technical partnership with MongoDB Basis Technology is partnering with MongoDB in order to let users integrate Rosette text analytics and multilingual search within MongoDB’s native in-database search. “One of the most important requirements for a database lies in being able to find the right data when you need it, and search is one of the most natural ways users can navigate the vast amounts of data generated by modern applications,” said Alan Chhabra, MongoDB’s vice president of partners. “We are excited to work with Rosette so MongoDB users can further enhance search for the critical data they need across multiple languages.”
Tue, 28 Jun 2016 12:00:00 -0500en-UStext/htmlhttps://sdtimes.com/basis-technology/mongodb-world-2016-sumo-logic-app-mongodb-infusions-collaboration-happiest-minds-r2m-solution-basis-technologys-technical-partnership/Airbyte Announces Certified Connectors for MongoDB, MySQL, PostgreSQL Databases Making Massive Amounts of Data Available for AI Modeling
Open source platform easily moves unlimited size data from popular databases to choice of 68 destinations including vector databases
SAN FRANCISCO, November 28, 2023--(BUSINESS WIRE)--Airbyte, creators of the fastest-growing open-source data integration platform, today announced availability of certified connectors for MongoDB, MySQL, and PostgreSQL databases, enabling datasets of unlimited size to be moved to any of Airbyte’s 68 supported destinations that include major cloud platforms (Amazon Web Services, Azure, Google), Databricks, Snowflake, and vector databases (Chroma, Milvus, Pinecone, Qdrant, Weaviate) which then can be accessed by artificial intelligence (AI) models.
Certified connectors (maintained and supported by Airbyte) are now available for both Airbyte Cloud and Airbyte Open Source Software (OSS) versions. The Airbyte connector catalog is the largest in the industry with more than 370 certified and community connectors. Also, users have built and are running more than 2,000 custom connectors created with the No-Code Connector Builder, which makes the construction and ongoing maintenance of Airbyte connectors much easier and faster.
"This makes a treasure trove of data available in these popular databases – MongoDB, MySQL, and Postgres – available to vector databases and AI applications," said Michel Tricot, co-founder and CEO, Airbyte. "There are no limits on the amount of data that can be replicated to another destination with our certified connectors."
Coming off the most recent Airbyte Hacktoberfest last month, there are now more than 20 Quickstart guides created by members of the user community, which provide step-by-step instructions and easy setup for different data movement use cases. For example, there are six for PostgreSQL related to moving data to Snowflake, BigQuery, and others. In addition, the community made 67 improvements to connectors that include migrations to no-code, which facilitates maintenance and upgrades.
Airbyte’s platform offers the following benefits.
The largest catalog of data sources that can be connected within minutes, and optimized for performance.
Availability of the no-code connector builder that makes it possible to easily and quickly create new connectors for data integrations that addresses the "long-tail" of data sources.
Ability to do incremental syncs to only extract changes in the data from a previous sync.
Built-in resiliency in the event of a disrupted session moving data, so the connection will resume from the point of the disruption.
Secure authentication for data access.
Ability to schedule and monitor status of all syncs.
Airbyte makes moving data easy and affordable across almost any source and destination, helping enterprises provide their users with access to the right data for analysis and decision-making. Airbyte has the largest data engineering contributor community – with more than 800 contributors – and the best tooling to build and maintain connectors.
Airbyte Open Source and connectors are free to use. Airbyte Cloud cost is based on usage with a pricing estimator here. To learn more about Airbyte and its capabilities, visit the Airbyte website.
About Airbyte
Airbyte is the open-source data movement leader running in the safety of your cloud and syncing data from applications, APIs, and databases to data warehouses, lakes, and other destinations. Airbyte offers four products: Airbyte Open Source, Airbyte Enterprise, Airbyte Cloud, and Powered by Airbyte. Airbyte was co-founded by Michel Tricot (former director of engineering and head of integrations at Liveramp and RideOS) and John Lafleur (serial entrepreneur of dev tools and B2B). The company is headquartered in San Francisco with a distributed team around the world. To learn more, visit airbyte.com.
Mon, 27 Nov 2023 22:00:00 -0600en-UStext/htmlhttps://finance.yahoo.com/news/airbyte-announces-certified-connectors-mongodb-170000268.htmlPinecone's CEO is on a quest to provide AI something like knowledgePinecone
ChatGPT and other generative AI programs spit out "hallucinations," assertions of falsehoods as fact, because the programs are not built to "know" anything; they are simply built to produce a string of characters that is a plausible continuation of whatever you've just typed.
"If I ask a question about medicine or legal or some technical question, the LLM [large language model] will not have that information, especially if that information is proprietary," said Edo Liberty, CEO and founder of startup Pinecone, in an interview recently with ZDNET. "So, it will just make up something, what we call hallucinations."
Liberty's company, a four-year-old, venture-backed software maker based in New York City, specializes in what's called a vector database. The company has received $138 million in financing for the quest to ground the merely plausible output of GenAI in something more authoritative, something resembling actual knowledge.
"The right thing to do, is, when you have the query, the prompt, go and fetch the relevant information from the vector database, put that into the context window, and suddenly your query or your interaction with the language model is a lot more effective," explained Liberty.
Vector databases are one corner of a rapidly expanding effort called "retrieval-augmented generation," or, RAG, whereby the LLMs seek outside input in the midst of forming their outputs in order to amplify what the neural network can do on its own.
Of all the RAG approaches, the vector database is among those with the deepest background in both research and industry. It has been around in a crude form for over a decade.
In his prior roles at huge tech companies, Liberty helped pioneer vector databases as an under-the-hood, skunkworks affair. He has served as head of research for Yahoo!, and as senior manager of research for the Amazon AWS SageMaker platform, and, later, head of Amazon AI Labs.
"If you look at shopping recommendations at Amazon or feed ranking at Facebook, or ad recommendations, or search at Google, they're all working behind the scenes with something that is effectively a vector database," Liberty told ZDNET.
For many years, vector databases were "still a kind of a well-kept secret" even within the database community, said Liberty. Such early vector databases weren't off-the-shelf products. "Every company had to build something internally to do this," he said. "I myself participated in building quite a few different platforms that require some vector database capabilities."
Liberty's insight in those years at Amazon was that using vectors couldn't simply be stuffed inside of an existing database. "It is a separate architecture, it is a separate database, a service -- it is a new kind of database," he said.
It was clear, he said, "where the puck was going" with AI even before ChatGPT. "With language models such as Google's BERT, that was the first language model that started picking up steam with the average developer," said Liberty, referring to Google's generative AI system, introduced in 2018, a precursor to ChatGPT.
"When that starts happening, that's a phase transition in the market." It was a transition that he had to jump on, he said.
"I knew how hard it is, and how long it takes, to build foundational database layers, and that we had to start ahead of time, because we only had a couple of years before this would become used by thousands of companies."
Any database is defined by the ways that data are organized, such as the rows and columns of relational databases, and the means of access, such as the structured query language of relational.
In the case of a vector database, each piece of data is represented by what's called a vector embedding, a group of numbers that place the data in an abstract space -- an "embedding space" -- based on similarity. For example, the cities London and Paris are closer together in a space of geographic proximity than either is to New York. Vector embeddings are just an efficient numeric way to represent the relative similarity.
In an embedding space, any kind of data can be represented as closer or farther based on similarity. Text, for example, can be thought of as words that are close, such as "occupies" and "located," which are both closer together than they are near a word such as "founded." Images, sounds, program codes -- all kinds of things can be reduced to numeric vectors that are then embedded according to their similarity.
Pinecone
To access the database, the vector database turns the query into a vector, and that vector is compared with the vectors in the database based on how close it is to them in the embedding space, what's known as a "similarity search." The closest match is then the output, the answer to a query.
You can see how this has obvious relevance for the recommender engines: two kinds of vacuum cleaners might be closer to each other than either is to a third type of vacuum. A query for a vacuum cleaner might be matched for how close it is to any of the descriptions of the three vacuums. Broadening or narrowing the query can lead to a broader or finer search for similarity throughout the embedding space.
But similarity search across vector embeddings is not itself sufficient to make a database. At best, it is a simple index of vectors for very basic retrieval.
A vector database, Liberty contends, has to have a management system, just like a relational database, something to handle numerous challenges of which a user isn't even aware. That includes how to store the various vectors across the available storage media, and how to scale the storage across distributed systems, and how to update, add and delete vectors within the system.
"Those are very, very unique queries, and very hard to do, and when you do that at scale, you have to build the system to be highly specialized for that," said Liberty.
"And it has to be built from the ground up, in terms of algorithms and data structures and everything, and it has to be cloud-native, otherwise, honestly, you can't really get the cost, scale, performance trade-offs that make it feasible and reasonable in production."
Pinecone
Matching queries to vectors stored in a database obviously dovetails well with large language models such as GPT-4. Their main function is to match a query in vector form to their amassed training data, summarized as vectors, and to what you've previously typed, also represented as vectors.
"The way LLMs [large language models] access data, they actually access the data with the vector itself," explained Liberty. "It's not metadata, it's not an added field that is the primary way that the information is represented."
For example, "If you want to say, provide me everything that looks like this, and I see an image -- maybe I crop a face and say, okay, fetch everybody from the database that looks like that, out of all my images," explained Liberty.
"Or if it's audio, something that sounds like this, or if it's text, it's something that's relevant from this document." Those sorts of combined queries can all be a matter of different similarity searches across different vector embedding spaces. That could be particularly useful for the multi-modal future that is coming to GenAI, as ZDNET has related.
The whole point, again, is to reduce hallucinations.
"Say you are building an application for technical support: the LLM might have been trained on some random products, but not your product, and it definitely won't have the new release that you have coming up, the documentation that's not public yet." As a consequence, "It will just make up something." Instead, with a vector database, a prompt pertaining to the new product will be matched to that particular information.
There are other promising avenues being explored in the overall RAG effort. AI scientists, aware of the limitations of large language models, have been trying to approximate what a database can do. Numerous parties, including Microsoft, have experimented with directly attaching to the LLMs something like a primitive memory, as ZDNET has previously reported.
By expanding the "context window," the term for the amount of stuff that was previously typed into the prompt of a program such as ChatGPT, more can be recalled with each turn of a chat session.
That approach can only go so far, Liberty told ZDNET. "That context window might or might not contain the information needed to actually produce the right answer," he said, and in practice, he argues, "It almost certainly will not."
"If you're asking a question about medicine, you're not going to put in the context window all of the knowledge of medicine," he pointed out. In the worst-case scenario, such "context stuffing," as it's called, can actually exacerbate hallucinations, said Liberty, "because you're adding noise."
Of course, other database software and tools vendors have seen the virtues of searching for similarities between vectors, and are adding capabilities to their existing wares. That includes MongdoDB, one of the most popular non-relational database systems, which has added "vector search" to its Atlas cloud-managed database platform. It also includes small-footprint database vendor Couchbase.
"They don't work," said Liberty of the me-too efforts, "because they don't even have the right mechanisms in place."
The means of access of other database systems can't be bolted to vector similarity search, in his view. Liberty offered an example of recall. "If I ask you what is your most recent interview you've done, what happens in your brain is not an SQL query," he said, referring to the structured retrieval language of relational databases.
"You have connotations, you can fetch relevant information by context -- that similarly or analogy is something vector databases can do because of the way they represent data" that other databases can't do because of their structure.
"We are highly specialized to do vector search extremely well, and we are built from the ground up, from algorithms, to data structures, to the data layout and query planning, to the architecture in the cloud, to do that extremely well."
What MongoDB, Couchbase, and the rest, he said "are trying to do, and, in some sense, successfully, is to muddy the waters on what a vector database even is," he said. "They know that, at scale, when it comes to building real-world applications with vector databases, there's going to be no competition."
The momentum is with Pinecone, argues Liberty, by virtue of having pursued his original insight with great focus.
"We have today thousands of companies using our product," said Liberty, "hundreds of thousands of developers have built stuff on Pinecone, our clients are being downloaded millions of times and used all over the place." Pinecone is "ranked as number one by God knows how many different surveys."
Revenue growth has clearly been substantial of late. Pinecone ended 2022 with $2 million of annualized recurring revenue, a measure of the total value of customer contracts. The company is ending this year with "tens of millions" of dollars in ARR, said marketing VP Greg Kogan, in an e-mail to ZDNET.
"Our growth was strong in 2022 and absolutely insane in 2023, owing to the fact that vector databases became a core component of GenAI and Pinecone always was and still is the market leader," wrote Kogan in e-mail. "We expect this to continue in 2024."
Going forward, said Liberty, the next several years for Pinecone will be about building a system that comes closer to what knowledge actually means.
"I think the interesting question is how do we represent knowledge?" Liberty told ZDNET. "If you have an AI system that needs to be truly intelligent, it needs to know stuff."
The path to representing knowledge for AI, said Liberty, is definitely a vector database. "But that is not the end answer," he said. "That is the initial part of the answer." There's another "two, three, five, ten years worth of investment in the technology to make those systems integrate with one another better to represent data more accurately," he said.
"There is a huge roadmap ahead of us of making knowledge an integral part of every application."
Wed, 27 Dec 2023 22:57:00 -0600entext/htmlhttps://www.zdnet.com/article/pinecones-ceo-is-on-a-quest-to-give-ai-something-like-knowledge/Nutrition Basics
Nutrition is a key part of overall health, and knowing basic information helps people make informed choices about what and how they eat. Understanding the benefits of different foods, as well as which foods to limit for overall health, creates a strong foundation for healthy eating throughout life.
Tue, 18 Aug 2020 17:45:00 -0500entext/htmlhttps://www.health.com/nutrition-basics-6951511Data 2024 outlook: Data meets generative AI
At the beginning of last year, who knew that generative artificial intelligence and ChatGPT would seize the moment?
A year ago, we forecast that data, analytics and AI providers would finally get around to simplifying and rethinking the modern data stack, a Topic that has been near and dear to us for a while. There was also much discussion and angst over data mesh as the answer to data governance in a distributed enterprise. We also forecast the rise of data lakehouses.
So how will all this play out in 2024? It shouldn’t be surprising that we see gen AI playing a major role with databases in the coming year with vector indexing, data discovery, governance and database design. But let’s start by reviewing how gen AI affected our predictions over the past year.
So what happened with data in 2023?
For the record, last year’s predictions are here and here. Turns out, many of them came true.
We saw real progress with simplifying and flattening the modern data stack through extension of cloud data warehousing services to integrate transactions, data transformation pipelines and visualization from the likes of SAP SE, Microsoft Corp., Oracle Corp. and others. And there was significant expansion by Amazon Web Services Inc. of its zero-ETL, or extract/transform/load, capabilities for tying together operational databases with Redshift and OpenSearch, addressing a key weakness in its database portfolio.
And as we expected, reality checks hit the data mesh, as enterprises grappled with the complexities of making federated data governance real. There is a new awareness for treating data as a product, but the definition of data products remains in the eyes of the beholder.
As for data lakehouses, which we termed as “the revenge of the SQL nerds,” Apache Iceberg became the de facto standard open table format bridging the data warehouse and lake together. Even Databricks Inc. opened the door by making Delta tables look like Iceberg.
But we interrupt this program
During the first quarter, there was hardly any mention of gen AI. But strangely, around April 1, the tech world pulled a 180-degree turn, as we noted in our gen AI trip report published back in the summer. Having been unleashed the previous November, OpenAI’s ChatGPT garnered 100 million users in barely a couple months; that’s a lot faster than Facebook, Instagram and what’s left of Twitter (X) ever did.
And suddenly, every data, analytics and AI solutions provider had to have a gen AI story. Vector data support became a checkbox feature with operational databases. English (and increasingly, other popular speaking languages) was fast becoming the world’s most popular application programming interface and software development kit. And there was humongous interest in the potential for gen AI to autogenerate coding, despite intellectual property issues.
Of course, generative transformer models work with more than language. They can also assemble pixels into a picture, spit out boilerplate code for requested functions, piece together musical notes to form songs, and work with molecular structures, geospatial and just about any other forms of data to find probabilistic connections. But most of the attention was on large language models.
Although everyone wants to be Nvidia’s BFF, the race is on for second sources. Scarcity of graphics processing units has gotten to the point where enterprises can only gain access through long-term, one-to three-year commitments for silicon for just-in-case capacity that is only likely to be about 20% utilized on average. Going meta here, we could see AI enabling an aftermarket of unused GPU cycles emerging for AI jobs.
Here’s the data angle: The success of every AI model – generative or classic machine learning – depends on the relevance, performance and accuracy of the model, and of course the relevance and quality of the data. In the new generative world, “garbage in, garbage out” remains as pertinent as ever.
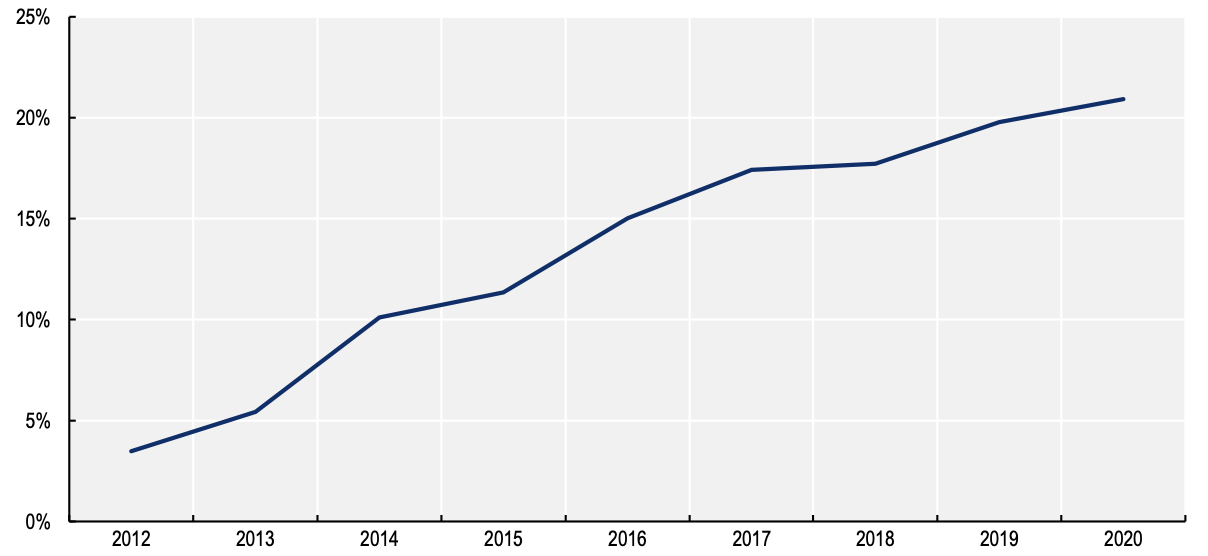
AI venture funding trends 2012-2020
Source: OECD.AI (2021), processed by JSI AI Lab, Slovenia, based on Preqin data of 4/23/2021, www.oecd.ai.
Setting the stage for 2024
A decade ago, data was the epicenter for venture funding. Glancing at our meeting schedules for the old Strata big data conferences of the 2010s, our agenda was crammed with startups providing lots of ancillary tools and services centered around Hadoop, streaming, catalogs and data wrangling.
Suffice it to say that there was a pretty high mortality rate, which is the Darwinian order of things. Fast-forward to today, and AI has supplanted data as hotspot for venture investment. According to the Organization for Economic Cooperation and Development, over the past decade, AI has been the fastest-growing sector for venture funding during that period, as shown in the chart, which extends only through 2020. A related fun fact from the OECD is that actual AI venture funding grew by 28 times over that period.
Admittedly, the last few years have been more fallow, but if the OECD chart were more current, we’d expect that growth in the percentage of venture deals and the multiples for AI would have continued.
According to PitchBook, the third quarter of 2023 saw overall venture financing dip to its the lowest level since 2017, with early-stage funding moving in unison with a five-year low. But the rich are getting richer, with Open AI as the obvious poster child with Microsoft’s $10 billion backing. And then there’s Anthropic PBC, with roughly $5 billion from AWS and Google LLC behind it, recently scoring another $750 million round, placing its valuation at a rather sublime $15 billion, or 75 times revenue.
The question isn’t whether, but when, there will be a popping of this bubble. With interest rates likely to decline next year, that moment of reckoning won’t likely come immediately. The tech is too new for customers to get disappointed. Yet.
But wait a moment. OpenAI, Anthropic, Cohere Inc. or otherwise, 2024 will likely be marked as the start of a Cambrian explosion of fit-for-purpose, and more compact, foundation models or FMs. We expect we’ll see an upswing of funding in this category to longer-tail firms.
Growth of these fit-for-purpose FMs will be driven by a backlash to the huge expense of running large models such as GPT. When it comes to LLMs, the meek (in the form of smaller language models) will inherit the Earth. With the learning curve, data scientists will grow more prescient at optimizing right-sized training data corpuses for generative models.
And as we noted a few months back, gen AI might be the shiny new thing on the block, but behind the scenes “classical” machine learning models will continue to perform the heavy lift. There will be more of a balance, using the right models for the right parts of the task, when the dust settles.
On the database side, we see a flight to safety. There is scant appetite for new database startups in a landscape that still counts hundreds of engines, but shows the top 10 most popular ones remaining largely stable. The usual suspects from three segments including the relational world (for example, Oracle, SQL Server and various dialects of MySQL and PostgreSQL), nonrelational databases (for example, MongoDB, Elastic, Redis) and the hyperscalers.
We’ll go out on a limb and state that the longer tail has limited prospects for growth. Couchbase Inc. is a good example of a second-tier player that, having recovered from a lost decade, has managed to eke out respectable growth, but it will never reach market share parity with MongoDB, with which it once vied. Beyond this group, we see scant prospects for 2010s-vintage startups such as Cockroach Labs Inc., Yugabyte Inc. or Aerospike Inc. displacing the established order.
So, what should we look for in the 2024 database landscape? A broad hint is that much of it will be about supporting and internally utilizing AI.
Vector indexes and BI integration will be the sleepers
Vector indexes won’t be the headline, and neither will gen AI-business intelligence integration. But this is where the most significant database innovation will come in 2024. Database vendors will expand on their generic vector index offerings today with a greater variety of optimized choices, and they will incorporate orchestration that allows gen AI queries to be enriched with tabular, BI-style results.
Back to basics, so what does gen AI have to do with databases? For running routine queries, it’s more efficient to persist the data rather than populate it on-demand. And for generative models, having access to new or more relevant data is key to keeping them current beyond the corpus of data on which the models were trained. That’s where retrieval-augmented generation, or RAG, and vectors come in.
Not surprisingly, the database sector responded last year by adding the ability to store vector embeddings. For existing operational databases, it was pretty much a no-brainer, as vectors comprise just another data type to add to the mix. AWS, DataStax Inc., Microsoft, MongoDB Inc., Snowflake Inc. and various PostgreSQL variants hopped the bandwagon.
We also saw emergence of specialized vector databases, such as from Pinecone Systems Inc. and Zillis Inc. with its Milvus. We expect that the vector database landscape will evolve in the same way as graph: A couple of specialized databases emerge for serving use cases that involve extreme scale and complexity, with most of the action coming from the databases that we already use that are, or are in the process of, adding vector data support as a feature.
With most operational databases adding vector storage, we view indexing as the next frontier, and that’s where much of the differentiation in gen AI support will come. Most databases adding vector storage are starting out with rudimentary indexing that is not optimized for specific service level agreements. That is about to change.
Here’s why: Vector indexes are not created equal. Vector indexes search for “nearest neighbors” that identify similar items (aka “similarity searches”), but there are different ways to optimize similarity searches that will in turn shape the choice of what databases to use based on which types of indexes they support.
Among the variables for vector indexes are recall rates, which measure the proportion of relevant data entities or items that are retrieved for a specific query. Essentially the choice is between low recall rates, which are quick-and-dirty approaches that are more economical to run and provide a general picture, and high-recall indexes that are more comprehensive and exacting with the results they return.
So, a generative application for producing marketing content could probably get by with a low-recall-rate vector index, whereas a compliance-related use case will require more comprehensive, and expensive, high-recall searches. There are other variations in vector indexes as well that are optimized for parameters such as speed (performance) or scale
For instance, Milvus offers nearly a dozen different vector index types optimized for data set size, speed, recall rates, memory footprint and dimensionality (a measure of query complexity), while Oracle offers a choice of an in-memory index for more compact searches and one designed to scale in parallel across multiple partitions.
The flip side of the coin is the ability to mix and match results of vector queries with tabular data. This will literally be the visible side of gen AI database innovation. For instance, a provider of market intelligence to business clients that delivers a natural language alternative to keyword searches, correlating summarized data on customer sentiment from the vector store with heterogeneous data from a document database such as MongoDB.
Here’s another use case: A manufacturer using gen AI to conduct root cause analysis of product quality issues can correlate with tabular data from a relational database tracking warranty and service costs. We expect to see better connective tissue inside database platforms that can orchestrate such compound queries.
Data and AI governance start coming together
Today, data governance and AI governance are separate toolchains, run by different practitioners: database administrators and data stewards at one end, and AI developers and data scientists on the other. The problem is not confined to gen AI, but applies to all types of AI models, and a convergence is long overdue. We expect to start seeing movement in the coming year toward bringing data and AI governance together through tracking and correlating lineage.
It’s a messy challenge. Just take data governance: In most organizations, it is hardly monolithic. Typically, different teams and players take the lead with data quality, security and privacy, compliance and risk management, and overall lifecycle management. And often these efforts will be overlapping, as most organizations have multiple tools such as data catalogs performing the same task.
The disconnect in data governance triggered the discussion over data mesh, which was about reconciling data ownership with responsibility for data products over their full lifecycle. That dominated the data discussion back in 2022.
Meanwhile, AI governance has emerged in spurts as adoption of machine learning spread from isolated proof of concepts toward becoming routinely embedded in predictive and prescriptive analytics. It typically focused on tracking model lineage, auditing, risk management, compliance and, in some cases, explainability. Gen AI has compounded the challenge, requiring more attention to citation of data sources while introducing new issues such as detecting (and enabling deletion) of toxic or libelous language; hallucinations (of course); and copyright and IP issues, to name a few examples.
The challenge, of course, is that with AI, models and data are intertwined. The performance, safety and compliance of a model is directly linked to both the training and production data sets that are used for generating answers. That is why, when detecting model bias, the problem could just as easily lie with the data or with logic or algorithm, or some combination of both.
For instance, it’s well-documented that the reliability of facial recognition systems gets easily skewed by over- or under-sampling of different races and nationalities. The same goes with analyzing demand for products or social services when different census tracts or demographic cohorts are sampled at different rates.
Then there is the question of drift; data and models can drift independently or interdependently. Data sources may change, and the trends in what the data is revealing may also require the model in turn to adapt its algorithms. You don’t want to be solving yesterday’s problem with today’s data or vice-versa.
In the coming year, we expect AI governance tools to start paying attention to data lineage. It is the logical point where the audit trails can begin, assessing which version of which model was trained on what version of what data, and who are the responsible parties that own and vouch for those changes.
From there, more sophiscated capabilities could later emerge, tracking and correlating data quality, accuracy, compliance and so on. With many machine learning models executing in-database, we see huge opportunity for data catalogs to incorporate model assets, and from there to become the point where governance is applied.
We viewed with interest that IBM closed the acquisition of Manta Software Inc. for data lineage around the same time that it took the wraps off watsonx.governance for AI governance. Although IBM’s timing was coincidental, we hope that it will eventually take advantage of this serendipitous opportunity.
Generative AI enriches data discovery and governance
It’s hardly surprising that the most popular use cases for gen AI have been around natural or conversational language interfaces for tasks ranging from query to coding. We expect that data discovery and governance will be a major target for gen AI augmentation in the coming year.
Let’s start with natural language or conversational query. A few good early examples include ThoughtSpot Sage, Databricks LakehouseIQ and Amazon Q in QuickSight that pick up where keyword-oriented predecessors such as Tableau Ask Data left off. We expect the Tableaus and Qliks of the world to respond in 2024.
We also expect that natural language will come to a variety of functions around the blocking and tackling involved with the data lifecycle, from cataloging data to discovering, managing, governing and securing it. Atlan, a data catalog provider focusing on DataOps provides glimpses of what we expect to see more of this year. Atlan starts with a common natural language search function that is quite similar to the natural language query capabilities that a growing array of BI tools are offering.
But it ventures further by adapting the autodiscovery of database metadata (for example, the table and columns names, schema specifications and lineage of the data asset) to generate documentation in plain English. As a mirror image to natural language SQL code generation, Atlan can translate existing SQL transformations into plain-language descriptions.
This is just the tip of the iceberg. A logical extension to these auto-documentation capabilities would extract data from business glossaries and correlate them with table metadata, or vice-versa. The automatic summarization capabilities of gen AI could be pointed at written policies, rules and incidents to document compliance with risk management guardrails. The memorizing of table metadata and SQL transformations could enrich or generate reference data that reconciles data between databases and applications, and identifying gaps or omissions. These are just a few of the possibilities that we expect will emerge this year.
Gen AI and database design
Following in the footsteps of automatic code generation or guidance, gen AI could also help database designers streamline development and deployment of databases. Of course, this will continue to require humans in the loop – we shouldn’t let a smart bot loose on designing a database without intervention. But the ability for language models to scan, summarize and highlight a corpus of data could make it a major productivity tool in database development.
Admittedly, AI is already being used in many aspects of database operation, from query optimization to index creation, autotuning, provisioning, patching and so on, with Oracle Autonomous Database being the poster child for complete self-driving automation. Although there are areas of operation where machine learning is already being used to optimize or provide suggestions that could be supplemented by gen AI, we believe that the biggest bang for the buck will be with aspects of the database dealing with the content of the data, and that’s where we expect the next wave of gen AI innovation will happen in 2024. As noted, we have already seen glimpses with natural language query and SQL code generation.
In the near term, we expect to see gen AI database innovation to focus on structuring the data. Taking advantage of the same types of capabilities that transformer models use for summarizing and extracting the highlights of documents, we could see this being applied to scanning requirements documentation for applications for data modeling through outputting E-R diagrams, schema generation, and synthetic data generation based on the characteristics of real data. And taking advantage of code generation capabilities and the ability to detect implicit data structure, we could see gen AI being applied to create data transformation pipelines.
Longer-term, we could see generative AI coming in to supplement the tasks where machine learning is already being applied, such as with index creation, error and outlier detection, and performance tuning. But we don’t view these functions as being first priority for database providers in 2024, as the benefits there will be incremental, not transformational. As with any shiny new thing, let’s not get carried away.
Tony Baer is principal at dbInsight LLC, which provides an independent view on the database and analytics technology ecosystem. Baer is an industry expert in extending data management practices, governance and advanced analytics to address the desire of enterprises to generate meaningful value from data-driven transformation. He wrote this article for SiliconANGLE.
Image: Bing Image Creator
Your vote of support is important to us and it helps us keep the content FREE.
One click below supports our mission to provide free, deep, and relevant content.
Join the community that includes more than 15,000 #CubeAlumni experts, including Amazon.com CEO Andy Jassy, Dell Technologies founder and CEO Michael Dell, Intel CEO Pat Gelsinger, and many more luminaries and experts.
“TheCUBE is an important partner to the industry. You guys really are a part of our events and we really appreciate you coming and I know people appreciate the content you create as well” – Andy Jassy
THANK YOU
Wed, 03 Jan 2024 00:00:00 -0600en-UStext/htmlhttps://siliconangle.com/2024/01/03/data-2024-outlook-data-meets-generative-ai/Car BasicsNo result found, try new keyword!Cars.com gets you up to speed with the latest news, expert reviews and advice to help you find the best car for your life. Ready to begin the car-shopping journey? Our experts walk you through the ...Thu, 04 Feb 2021 05:01:00 -0600https://www.cars.com/explore/car-basics/What Is A CNA? Education Requirements And Job Description
Editorial Note: We earn a commission from partner links on Forbes Advisor. Commissions do not affect our editors' opinions or evaluations.
Certified nursing assistants (CNAs) are responsible for some of their patients’ most intimate personal care needs. While doctors and registered nurses (RNs) tackle the higher-level and more critical elements of patient care, such as diagnosing and treating patients, CNAs are often the primary caregivers for patients who need basic assistance in meeting their daily care needs.
If you are interested in helping others on a personal level in a healthcare setting, and you don’t want to spend years earning a nursing degree, becoming a CNA may help you reach your goals. In this guide, we explore how to become a CNA, including common responsibilities, work environments and qualifications for these professionals.
What Does a Certified Nursing Assistant Do?
CNAs provide care to patients and assist them with their daily activities. These professionals may work in hospitals, residential care facilities or other healthcare settings. They work under the supervision of licensed nursing staff.
While job duties may vary, typical responsibilities for CNAs may include:
Assisting patients with bathing, dressing, grooming or using the restroom
Monitoring vital signs, such as blood pressure and heart rate
Serving meals and assisting patients with eating
Turning or repositioning patients who may be confined to bed
Transporting patients or transferring them to and from their wheelchairs and beds
Recording information and reporting to nursing staff
Answering patient calls
Stocking supplies
Caring for wounds
Assisting with medical procedures
Where Do CNAs Work?
CNAs work in virtually any setting where patients need medical care, whether in hospitals, medical facilities or patients’ homes. These professionals work under the supervision of licensed nurses or doctors to help patients manage their temporary or long-term medical needs. Below we discuss the typical work environments for CNAs.
Skilled Nursing Care Facilities
CNAs who work in nursing care facilities help residential patients with personal care and daily living activities, such as bathing, grooming and eating. They also monitor vital signs and help patients with their mobility. CNAs in these settings may also provide residential patients with companionship and assistance with social activities.
CNAs working in skilled nursing care facilities earn a median annual salary of $35,480, according to the U.S. Bureau of Labor Statistics (BLS).
Home Healthcare Services
CNAs who work in home healthcare services allow patients to remain in their homes while receiving care. This care may include bathing, eating, grooming and using the restroom, along with monitoring vital signs and providing mobility assistance.
CNAs who provide home healthcare services may work with patients of any age, including seniors and those who are living with disabilities. These professionals earn a median annual salary of $31,280, according to the BLS.
Hospitals
CNAs who work in hospitals perform a variety of tasks related to assisting RNs with patient care. This may include monitoring vital statistics, repositioning patients and transferring patients between their wheelchairs and beds.
CNAs working in hospitals earn a median annual salary of $36,480, as reported by the BLS.
Assisted Living Facilities
CNAs who work in assisted living facilities help patients with basic personal care and daily living activities, such as bathing, grooming and eating. In some situations, these CNAs work with patients who are more independent and may only need help with monitoring their medical conditions, mobility assistance or light housekeeping.
The BLS reports that CNAs working in assisted living facilities earn a median annual salary of $34,600.
Government Facilities and Agencies
CNAs who work in the government sector provide personal care services and assistance with daily living activities to patients in government facilities and agencies, such as Virginia hospitals and federal correctional facilities.
These CNAs earned a median annual salary of $37,310, according to the BLS.
Steps to Becoming a CNA
Completing a CNA training program prepares graduates to work as certified nursing assistants. Each state sets different requirements for CNA training programs, so specifics may vary according to where you live. Even so, some basic requirements are common among most CNA programs.
Earn a High School Diploma or Equivalent
While many nursing careers require college degrees, such as an associate in nursing or a BSN degree, you don’t need a college degree to become a CNA. In most cases, prospective CNAs need a high school diploma, a GED® diploma or its equivalent to enroll in a CNA training program.
Complete Nursing Assistant Training
You can complete your CNA training at a trade school, community college, medical facility or another training organization in your community, such as the Red Cross. Make sure to research programs carefully to make sure they are approved by your state’s board of nursing.
CNA training covers essential skills and knowledge by focusing on theory, laboratory practice and clinical experience. Later in this article, we discuss what you can expect from a CNA training program.
Pass a CNA Certification Examination to Become Certified
After you have finished your CNA training, you must pass an examination to become certified. Each state sets its own CNA test requirements through its state board of nursing. In most cases, however, you should expect a written or oral portion, plus a clinical skills portion in which you demonstrate your skills as a CNA.
The National Nurse Aide Assessment Program offers a standardized CNA test in 18 jurisdictions. Check with your state’s nursing board for more information about certification examinations.
Common Elements of CNA Training Programs
Every CNA program is different, but the following are common elements of most CNA training programs.
Theory and Lab Training
This element of CNA training teaches the essential skills needed to properly care for patients. These include how to bathe, feed and position patients and monitor their vital signs. The lab portion of CNA training provides hands-on experience by allowing students to practice these skills.
Clinical Training
The clinical element of CNA training allows learners to work directly under the supervision of instructors who are licensed RNs. This part of the training allows students to apply the knowledge gained in their program by providing patients with care.
Salary and Job Outlook for CNAs
CNAs earn a median annual salary of $35,760, as reported by the BLS. You should be aware, though, that nursing assistants’ salaries vary depending on work setting and location.
In hospitals, for example, the median annual salary is $36,480. In home healthcare settings, it’s $31,280. The highest-paid CNAs are in Alaska, where the average annual salary is $44,420. In Oregon, for comparison, CNAs make $42,960 per year on average.
Frequently Asked Questions (FAQs) About CNAs
CNAs assist nurses by monitoring patients’ vital signs and helping them with basic personal care. CNAs also provide assistance with patients’ daily living activities, such as bathing and grooming.
Is a CNA the same as a nurse?
No, the two professions are different. CNAs work as assistants in nursing settings under the supervision of nurses and other medical providers. They care for patients’ personal needs to help reduce nurses’ workloads. Nurses face more stringent licensing requirements than CNAs, such as needing a degree.
CNA training programs should provide the knowledge and skills necessary to pass the CNA exam. This test should not be difficult, but if you are concerned about taking the exam, there are practice tests available online that you can use to better prepare yourself to take the exam.
How Long Does it Take to Become a CNA?
The time required to complete a CNA training program varies. These programs typically take anywhere from three weeks to three months to complete.
Tue, 02 Jan 2024 02:38:00 -0600Sheryl Greyen-UStext/htmlhttps://www.forbes.com/advisor/education/what-is-a-cna/
Exam Simulator 3.0.9 uses the actual MongoDB C1000DEV questions and answers that make up Exam Braindumps. C1000DEV Exam Simulator is full screen windows application that provide you the experience of same test environment as you experience in test center.
We are a group of Certified Professionals, working hard to provide up to date and 100% valid test questions and answers.
Who We Are
We help people to pass their complicated and difficult MongoDB C1000DEV exams with short cut MongoDB C1000DEV Exam Braindumps that we collect from professional team of Killexams.com
What We Do
We provide actual MongoDB C1000DEV questions and answers in Exam Braindumps that we obtain from killexams.com. These Exam Braindumps contains up to date MongoDB C1000DEV questions and answers that help to pass exam at first attempt. Killexams.com develop Exam Simulator for realistic exam experience. Exam simulator helps to memorize and practice questions and answers. We take premium exams from Killexams.com
Why Choose Us
Exam Braindumps that we provide is updated on regular basis. All the Questions and Answers are verified and corrected by certified professionals. Online test help is provided 24x7 by our certified professionals. Our source of exam questions is killexams.com which is best certification exam Braindumps provider in the market.
97,860
Happy clients
245
Vendors
6,300
Exams Provided
7,110
Testimonials
Premium C1000DEV Full Version
Our premium C1000DEV - MongoDB Certified Developer Associate contains complete question bank contains actual exam questions. Premium C1000DEV braindumps are updated on regular basis and verified by certified professionals. There is one time payment during 3 months, no auto renewal and no hidden charges. During 3 months any change in the exam questions and answers will be available in your download section and you will be intimated by email to re-download the exam file after update.
Contact Us
We provide Live Chat and Email Support 24x7. Our certification team is available only on email. Order and Troubleshooting support is available 24x7.














{kind=link}